Chapter 5 Inference and statistical tests
- Understand statistical test reasoning
- Interpret results of a statistical test
- Discuss significance of a statistical test
The aim of a statistical test is to reach a scientific decision on a difference (or effect), on a probabilistic basis, based on observed data.
When assessing differences between groups (Who), you have to define What to compare. According to the type of the variable, you will choose a statistical parameter (mean, proportion, data distribution) to perform the comparison. The comparison will be based on hypothesis, with possible assumption to verify, and the associated statistical test.
In summary, the procedure is as follow:
- Formulate hypothesis to be tested
- Choose the appropriate statistical test
- Calculate the appropriate statistic measure
- Interpret the result
5.1 Formulate a hypothesis
In hypothesis formulation you always have two possibilities: it is not different OR it is different.
In the HBSC data, we are interested in the characteristics of the smoking students compare to the non-smoking. Do they differ by some characteristics?
Example 5.1 We would like to test whether there is, on average, a difference in height between smokers and non-smokers.
Example 5.2 We would like to test if the proportion of smokers varies by gender.
First, we describe the distribution of the variable between the groups.
In example 5.1, the height is a quantitative continuous variable which can be summarized by the mean (Table 5.1). In our sample, the students who do not smoke measure on average 157 cm while the students who smoke measure in average 166 cm. The question is “At the population level, is that different knowing that you do have individual variation (SD) and sample variations (SE)?”
| SmokingStatus | Mean | SD | Median | Q1 | Q3 |
|---|---|---|---|---|---|
| 0 | 157.89 | 12.00 | 159 | 149 | 166.25 |
| 1 | 166.26 | 11.39 | 168 | 159 | 173.00 |
In example 5.2, the gender is a qualitative variable which can be summarized into proportions (Table 5.2). In our sample, the proportion of students seem to different between groups. The question is “At the population level, are those proportions real different knowing that you do have individuals’ variation (sd) and sampling variation (se)?”
| Gender | No | Yes |
|---|---|---|
| boy | 85.26 | 14.74 |
| girl | 87.90 | 12.10 |
In theory, we test whether the two groups (samples) come from the same population (Figure 5.1). For instance, sample 1 with mean m1 from population 1 with \(\mu_1\) is coming from the same population as sample 2 with mean m2 from population 1 with \(\mu_2\). Population 1 is equal to population 2.
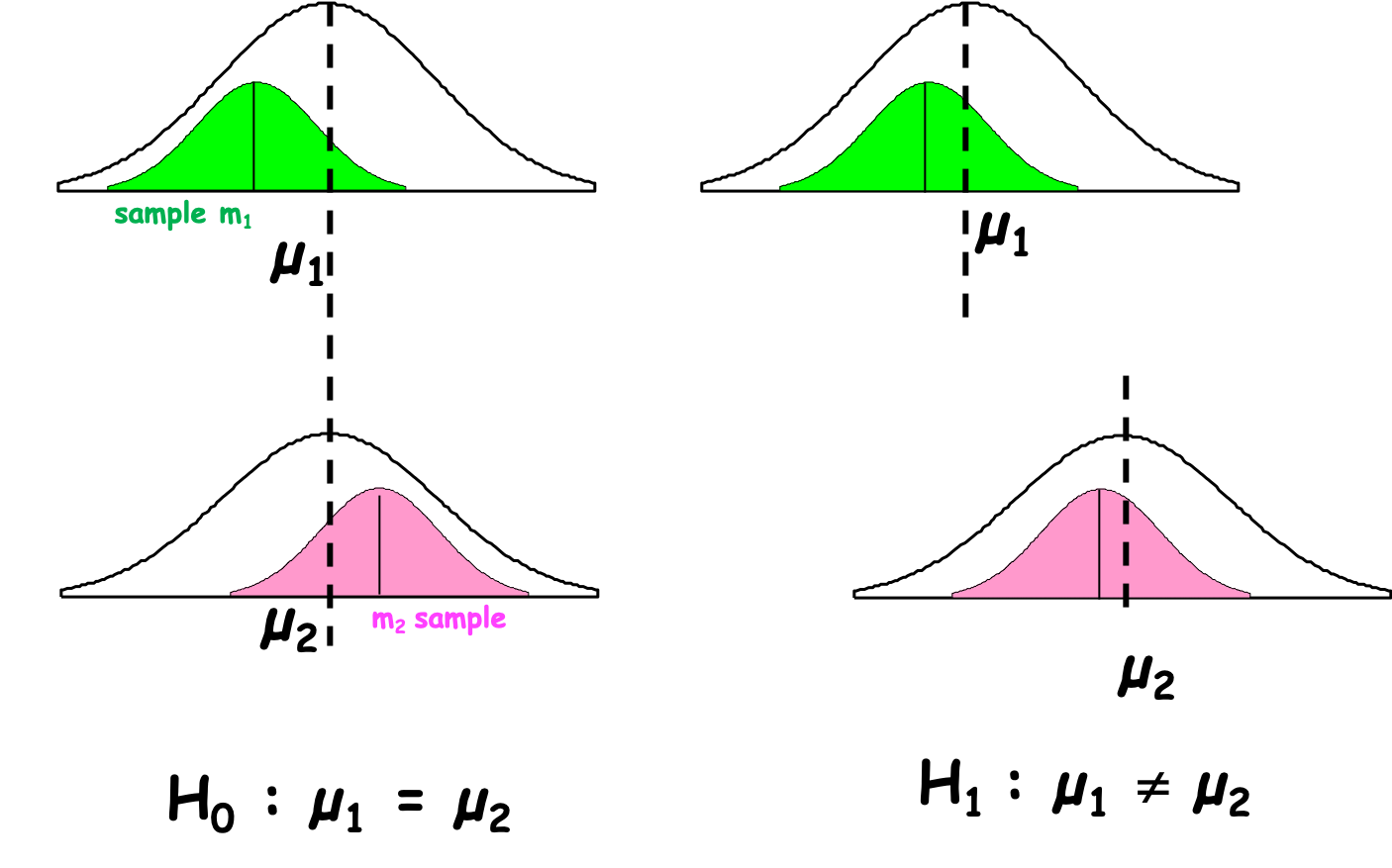
Figure 5.1: Population versus Sample
When you state the hypothesis you should explicit H0 an H1.
Definition 5.1 H0 : The null hypothesis is that the parameters are EQUAL, i.e they are not different.
H1: The alternative hypothesis is that the parameters are NOT EQUAL, i.e they are different.
I like to write down the hypothesis with the \(=\) sign and \(\neq\) as I find easier to pick the test and interpret the results afterward.
Remember the W’s they should appear in the hypothesis if you have the information.
Example 5.3 We would like to test whether there is, on average, a difference in height between smokers and non-smokers.
H0: In France in 2006, the mean height of the students 11-16 who smoke was equal to the mean height of the students 11-16 who do not smoke.
H1: In France in 2006, the mean height of the students 11-16 who smoke was NOT equal to the mean height of the students 11-16 who do not smoke.
Example 5.4 We would like to test if the proportion of smokers varies according by gender.
H0: In France in 2006, the proportion of student girls aged 11-16 in the smoker group was equal to the proportion of student girls aged 11-16 in the non-smoker group
H1: In France in 2006, the proportion of student girls aged 11-16 in the smoker group was NOT equal to the proportion of student girls aged 11-16 in the non-smoker group
A statistical test is always performed to answer the H0 hypothesis (Figure 5.2).
- When we prove that the statistical parameters differ we reject H0 and accept H1. We say that we observed a statistically significant difference between the parameters.
- When we cannot prove that the statistical parameters differ, we stay under H0 and say that: we fail to reject H0 because we cannot show any statistically significant difference. H0 is never accepted as an error risk still exists that we can not compute.
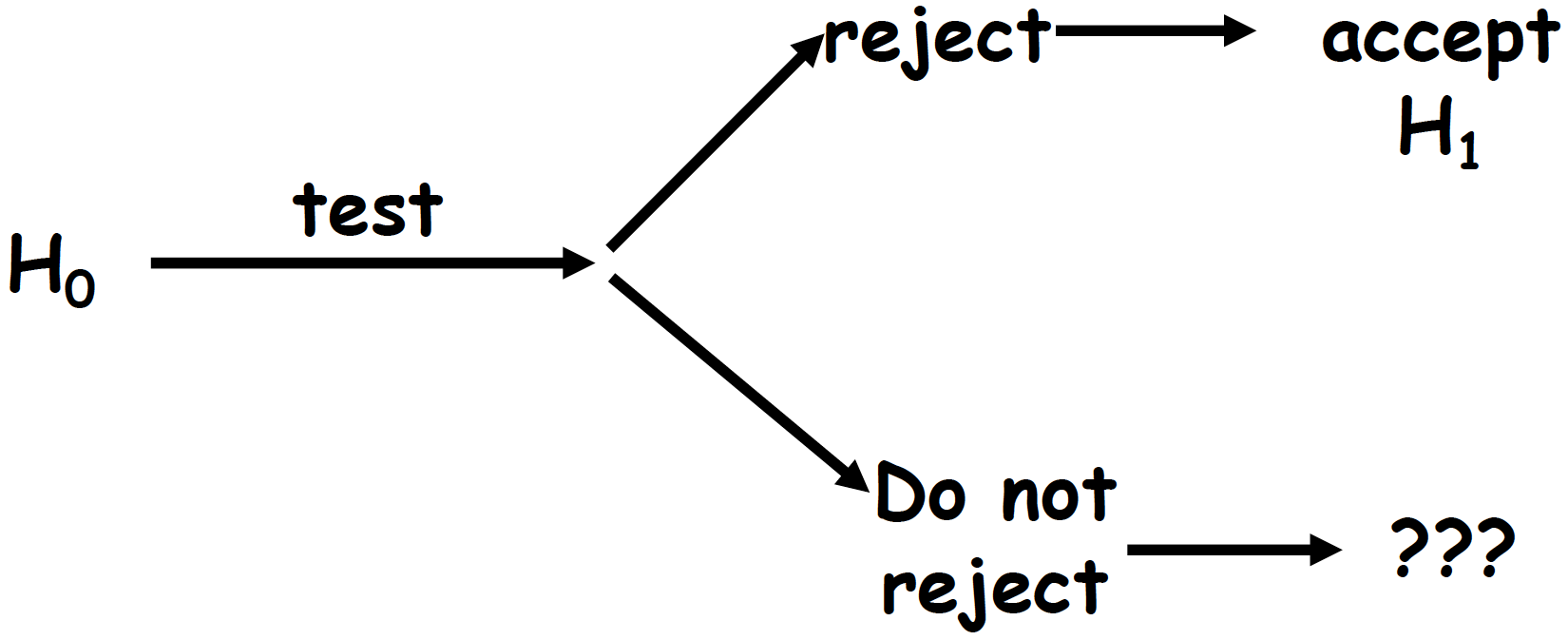
Figure 5.2: Statistical test interpretation
5.2 Comparison of two means
Once the hypothesis are stated, we choose a test. In the context if the comparison of means, the test will assess whether the observed difference (\(\Delta\)) between the two groups is random (due to individuals’ and sampling variations) or not (Figure 5.3).
In theory, if H0 is true \(\Delta = m_1 - m_2 = 0\)
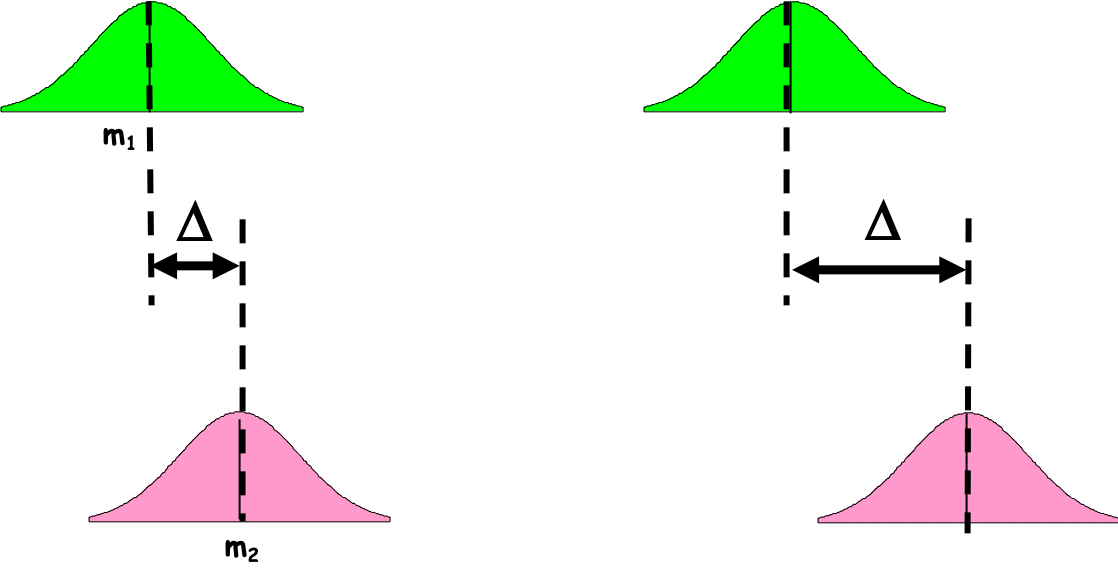
Figure 5.3: Population versus Sample
But we never compare \(\Delta\) to 0 as we need to take into account the individuals’ fluctuation (sd) and sampling (se) variation. What is the critical value, then ? Can you guess ?
The critical value depends on the risk you are willing to take to conclude about a difference that does not exist in reality, the \(\alpha\) risk.
When comparing means, you make the assumption that your sample’s distributions are not too different from a Normal distribution. Therefore, the difference \(\Delta=m_1-m_2\) should follow a Normal distribution centered on 0. Then to take into account the individuals and sampling variation, the difference is standardized. The statistical value \((m_1-m_2)/s_\Delta\) is computed and compare to the critical value \(Z_\alpha\) of the centered reduced Normal distribution for a risk \(\alpha\). [Note \(s_\Delta\) is function of the chosen test]
For a risk \(\alpha=5\)% the critical value is \(Z_\alpha=1.96\).
If H0 is true, 95% of values of \((m_1-m_2)/s_\Delta\) are between -1.96 and 1.96. If the statistical value \((m_1-m_2)/s_\Delta\) returned by your test is above 1.96 or below -1.96, you reject H0 and accept H1.
In example 1, the statistical value for a risk \(\alpha=0.05\) is -5.4582. What is you conclusion?
5.3 Comparison of two proportions
In the context of proportion comparison like in example 2, the objective is to assess whether the proportion of cases among the exposed group is equal to the proportion of cases among the non-exposed group.
Example 5.5 We would like to test if the proportion of smokers varies by gender.
H0: In France in 2006, the proportion of student boys aged 11-16 in the smoker group was equal to the proportion of student girls aged 11-16 in the smoker group
H1: In France in 2006, the proportion of student boys aged 11-16 in the smoker group was NOT equal to the proportion of student girls aged 11-16 in the smoker group
To this aim, we will compute the standardized differences (distances) between groups.
5.3.1 Chi-square test
The Chi-square is often the test used as rather intuitive and non computer greedy.
First, we compute a two-way table with your observed counts:
| Gender | No | Yes | Total |
|---|---|---|---|
| boy | 214 | 37 | 251 |
| girl | 218 | 30 | 248 |
| Total | 432 | 67 | 499 |
Under H0 the absence of difference (independence assumption), we would expect to have the same proportion of smokers among the girls and the boys. So keeping the total margins what would be the expected counts? (Table 5.4)
| No | Yes | Total | |
|---|---|---|---|
| boy | ? | ? | 251 |
| girl | ? | ? | 248 |
| Total | 432 | 67 | 499 |
To compute a theoretical two-way table with your expected counts:
- the proportion exposed students is: \(p= 67/499= 0.134\), i.e 13.4%.
- the number of boys students exposed would be: \(p= (67/499)*251 = 33.7\).
| No | Yes | Total | |
|---|---|---|---|
| boy | ? | (67/499)*251 | 251 |
| girl | ? | ? | 248 |
| Total | 432 | 67 | 499 |
| No | Yes | Total | |
|---|---|---|---|
| boy | 217.3 | 33.7 | 251 |
| girl | 214.7 | 33.3 | 248 |
| Total | 432 | 67 | 499 |
Then we compute the Chi-square (\(\chi^2\)) statistic which is the standardized sum of the differences between the observed and the expected values.
\(\chi^2_{Obs}= \sum(\dfrac{(Obs-Exp)^2}{Exp}\)
Using the R statistical software, we have
##
## Pearson's Chi-squared test with Yates' continuity correction
##
## data: hbsc$Gender and hbsc$SmokingStatus
## X-squared = 0.54013, df = 1, p-value = 0.4624The \(\chi^2_{Obs} = 0.54\). Now the question is:
“Is \(\chi^2_{Obs}\) equal to 0?”
As for the comparison of means, in theory, if H0 is true \(\chi^2_{Obs} \sim 0\) but it is never 0. There are variations and we test H0 with a \(\alpha\) risk. Therefore, what is the threshold?
To define that threshold, we need to choose the correct statistical law. The \(\chi^2\) distribution depends on k, the number of degrees of freedom (df) which depends on the number of characteristics of the two variables we are comparing (Figure 5.4).
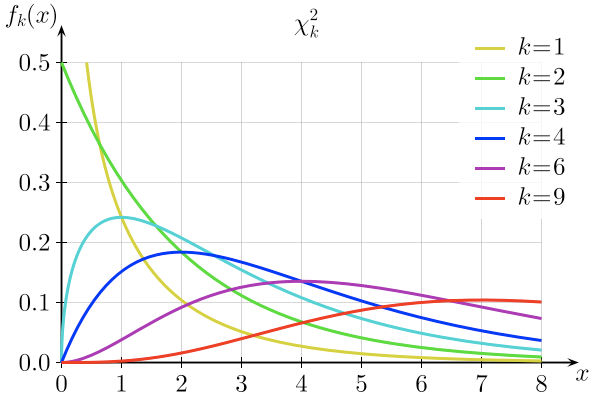
Figure 5.4: Chi2 distribution depends on the degree of fredom K
When the two-way table of the expected number is drawn, the degree of freedom is the number of values in the final calculation that are free to vary. For instance, in a 2x2 table once you have set one value the others cannot change. The quick formula to compute the degree of freedom (df) for the \(\chi^2\) distribution is the number of rows in the table minus 1 multiply by the number of columns in the table minus 1:
df = (#rows - 1) * (#cols - 1)
For a 2x3 table, what is the degree of freedom?
Next, we need to look at the statistical table of the \(\chi^2\) law (Figure 5.5). The threshold value also depends on the \(\alpha\) risk you are willing to take.
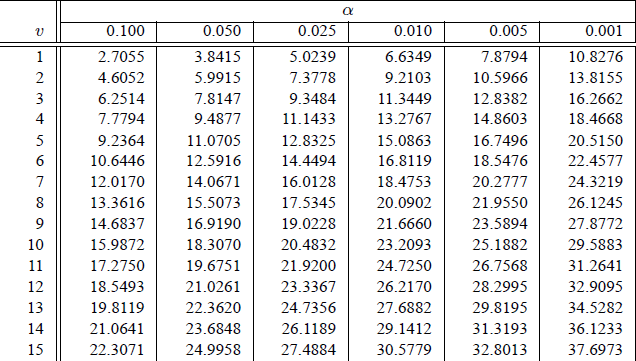
Figure 5.5: Chi2 distribution depends on the degree of fredom K
In the \(\chi^2\) table, for our 2x2 table the \(df = 1\) and for a \(\alpha\) risk of 5%, the \(\chi^2_{Theo}= 3.84\).
Next the decision rule using the p-value is the same as for the comparison of means.
In the example, the statistical value for a risk \(\alpha=0.05\) and \(df=1\) is 3.84. The \(\chi^2_{Obs} = 0.54\). What is you conclusion?
To correctly use the \(\chi^2\) test and have accurate estimation of the associated probabilities, we need to have at least n=5 count in each cell of the table of expected numbers.
5.3.2 Fisher’s Exact test
To compare proportions the Fisher’s Exact test is even better than \(\chi^2\) as it computes the exact probability of obtaining a difference even greater if H0 is true. However the formula is more complex and difficult to compute by hand . A computer is highly recommended (Table 5.7).
| No | Yes | Total | |
|---|---|---|---|
| boy | a | c | n1 |
| girl | b | d | n2 |
| Total | t1 | t2 | N |
\(p = \dfrac{n_1!n_2!t_1!t_2!}{a!b!c!d!}\)
Using the R statistical software, we have
##
## Fisher's Exact Test for Count Data
##
## data: hbsc$Gender and hbsc$SmokingStatus
## p-value = 0.4316
## alternative hypothesis: true odds ratio is not equal to 1
## 95 percent confidence interval:
## 0.4571282 1.3779096
## sample estimates:
## odds ratio
## 0.7962999How to read the output of the Fisher’s Exact test?
- We can look at the odds ratio and the confidence interval (95% CI)
As it is a ratio (numerator/denominator) if there is no difference (numerator=denominator) the \(odds ratio \sim 1\). However it is never 1, we need to look at the confidence interval (at a certain risk level) to conclude.
- If the confidence interval includes 1, we fail to reject H0, we can not conclude that the proportions differ.
- If the confidence interval does not include 1, we reject H0, the proportions differ.
In the example, the Fisher’s exact test returns an odds ratio of 0.79 and 95% CI [0.45, 1.37]. What is your conclusion?
- We can look at the \(p-value\) but what is a \(p-value\) ? See next section 5.4.
5.4 Risk \(\alpha\) and \(p-value\)
The demonstrations above and the use of \(Z_\alpha\) or \(\chi^2_\alpha\) values are valid for comparison of means or proportions under some assumptions and conditions (\(Z_\alpha\) with sample size above 30 in each group; \(\chi^2_\alpha\) function df…). What is happening for other tests?
The philosophy is exactly the same but the critical value might come from other statistical laws than the Normal law (Chi-square, Binomial, Poisson…). It might be difficult to retrieve the critical value need to compare to your computed statistical value. There are more statistical tables that there are statistical tests.
The common practice is then to compare the risk \(\alpha\), defined a priori, to the \(p-value\) returned by the test a posteriori.We want to know the ultimate risk that is taken. Meaning, the risk corresponding to the value found by the test.
\(\alpha\) risk and \(p-value\)
\(\alpha\) risk: a priori risk to conclude about a difference that does not exist in reality
\(p-value\): a posteriori error risk that is taken knowing the result of the test
Statistical test’s decision rule
When \(p-value\) > \(\alpha\) risk, we FAIL to reject H0
When \(p-value \leq \alpha\) risk, we reject H0
The \(p-value\) is not synonymous of the importance of the possible difference between groups. In other words, a very small p-value means that the risk of making a mistake is very low. It does not mean that there is a huge difference between groups.
Example 5.6 Example 3: Using 2 studies we are assessing 2 new methods (A and B) for the prevention of surgical site infections (SSI) compared to a conventional method (0).
- In study A: method A shows 12% of SSI and the conventional method 24% of SSI. The test between A and 0 returns a \(p-value \leq 0.05\).
- In study B: method B shows 12% of SSI and the conventional method 24% of SSI. The test between B and 0 returns a \(p-value \leq 0.001\)
Is method B better than method A in preventing SSI?
In the example above, we cannot tell if method B is better than method A : we did not test A versus B. The only information we get is that method A is different from method 0 and that method B is different from method 0. In fact method A and B present the same level of SSI. They might not be different but to conclude (with a certain level of confidence) we need to do a test. (see section 5.7 for comparison of multiple groups)
In example 1, we tested H0 with the Student’s T test. The \(p-value\) is 4.342e-07. What is your conclusion?
In example 2, we tested H0 with a \(\chi^2\) test. The \(p-value\) is 0.462. What is your conclusion?
We also tested H0 with the Fisher’s Exact test. The \(p-value\) is 0.431. Do you reach the same conclusion than with the \(\chi^2\) test? Why?
If you try to compare the effects of different risk factors or compare similar studies but with different protocols, you sholud not compare the p-values. A p-value smaller than an other p-value does not mean that the observed difference is greater. It only means that your are more confident on the results of the test.
You should not compare p-values.
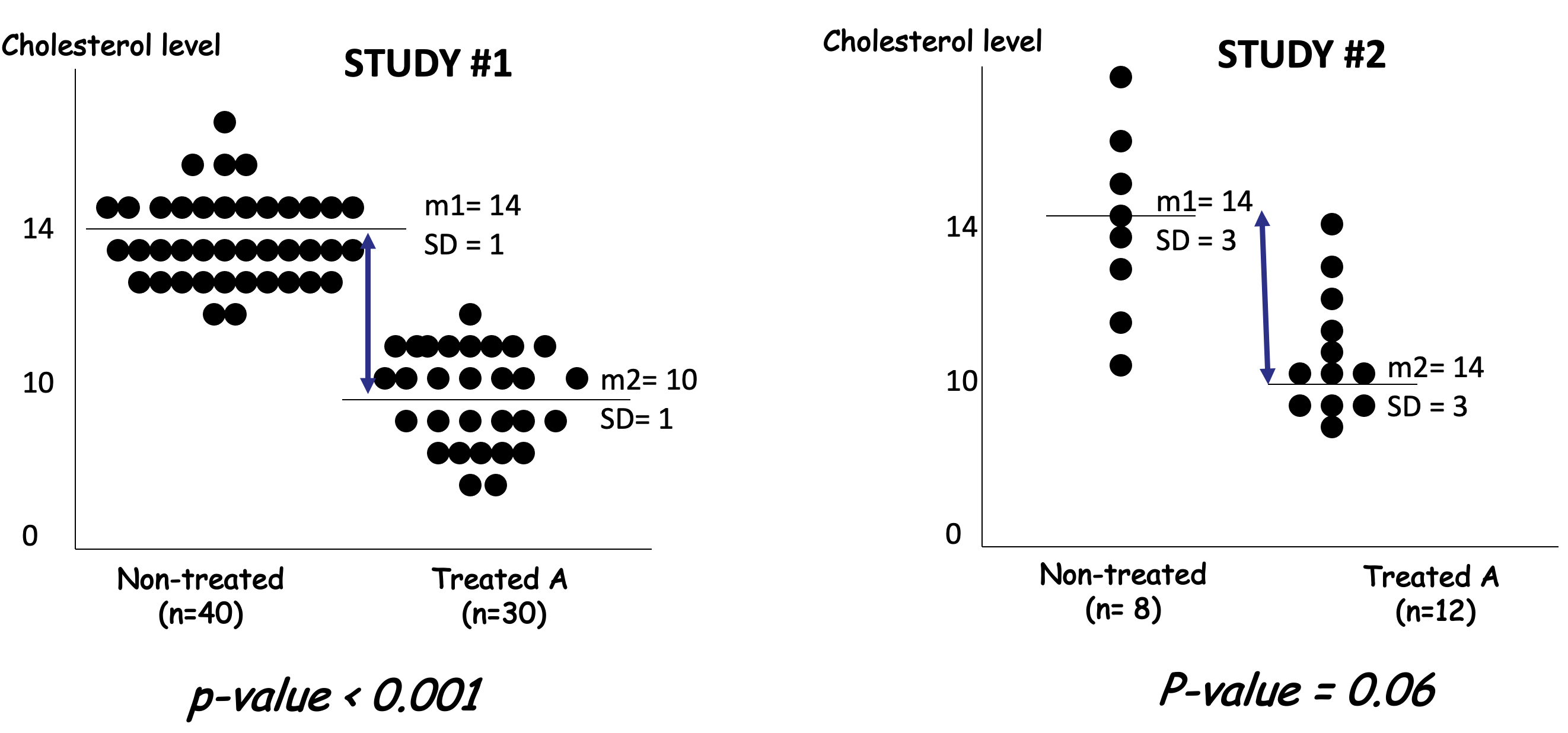
In the cholestrol studies presented above, the p-values are different, one is smaller than the other (even significant). Although the observed differences in mean are identical. The difference is the same in study 1 and 2 (\(\delta=4\)). The differences between the two studies are on the standard deviations of the samples and the sample sizes which affect the t-statistics.
5.5 Risk \(\alpha\) and risk \(\beta\)
Why do we not accept H0?
As mentioned earlier there is always a risk of being wrong (Figure 5.6) but that risk cannot be computed. It is \(\beta\).
In row the unknown truth, in column the conclusion of the test.

Figure 5.6: Where do the risks stand?
- \(\alpha\) is the probability of rejecting H0, when H0 is true (Figure 5.7)
- \(\beta\) is the probability of failing to reject H0, when H1 is true (Figure 5.8)

Figure 5.7: Population versus when it does not exist
Imagine that you are the “eyes” and you are unable to see the perspective above the horizon. You will believe that the 2 lines make 1 and that they are of the same length but in reality the further away is longer. That is the \(\beta\) risk.
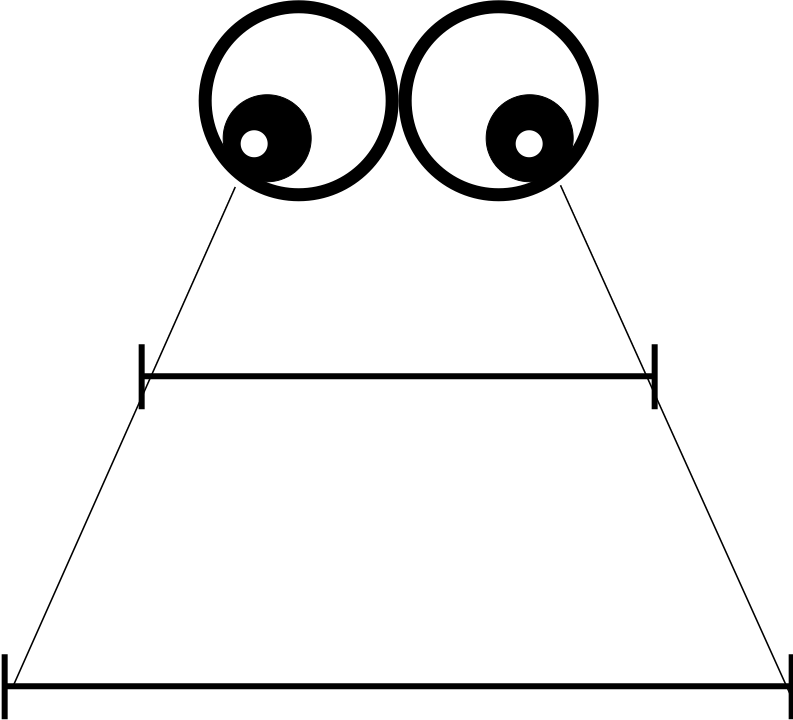
Figure 5.8: Not seeing a difference when it does exist.
What do you prefer \(\alpha\) or \(\beta\) ?
It is a difficult question.
Example 5.7 Example 4: Hepatitis B vaccination and multiple sclerosis. Many study protocols have been conduct to assess an possible association between vaccination against Hepatitis B and the development of multiple sclerosis. The null hypothesis was that prevalence of multiple sclerosis was the same among people vaccinated against Hepatitis B and people not vaccinated against Hepatitis B.
In that context, what would you favour \(\alpha\) or \(\beta\)?
- Wrongly reject H0 and conclude that there is an effect : it could be catastrophic as the immunization coverage will fall down
- Not seeing an effect: people may not get Hepatitis B vaccination but multiple sclerosis !!!
Note that there have been many studies on the above question and that no effect as been seen so far.
You test the hypothesis of an absence of difference in school grades between gender. What is your conclusion if:
\(p-value = 0.049\)
\(p-value = 0.051\)
Comment on your conclusions.
5.6 Comparison of multiple groups
Example 5.8 Example 5: We are interested in the effect of 2 treatments to gain weight. The protocol include treatment A, treatment B, and a placebo group. We would like to compare the weights between the 3 groups.
How do we compare the means? Can we do 2 by 2 comparisons?
Table 1: Effects of 2 treatments to gain weight
| Parameters | Treatment A | Treatment B | Placebo |
|---|---|---|---|
| sample size n | 62 | 62 | 96 |
| mean weight | 66.06 | 63.83 | 62.32 |
| sd weight | 3.18 | 2.16 | 3.12 |
To the above question the answer is “No” : it increases the likelihood of incorrectly concluding that there are statistically significant differences, since each comparison adds to the probability of a type I error, \(\alpha\).
At the end, if \(k\) is the number of comparisons, the error rate becomes \(1-(0.95)^k\)
5.6.1 Graphical comparison
A boxplot and whisker plot (section 3.4) is an ideal graphical representation to compare data series of the same variable between different groups.
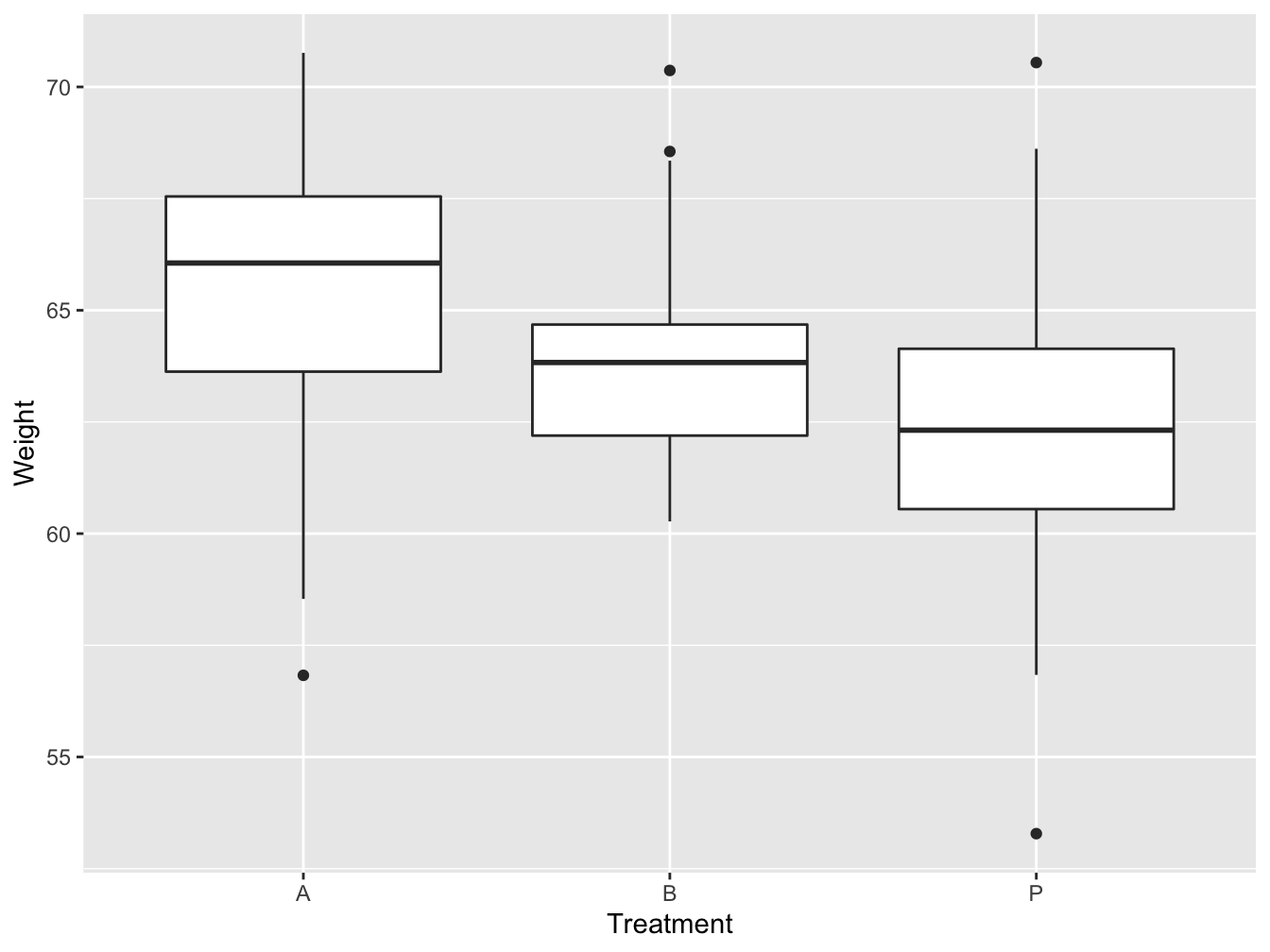
Figure 5.9: Boxplot and whisker plot of the effect of different treatments on gain weight
Figure 5.9 shows that the distributions seems to differ. The median (black line with the box) are located at differ weight.
What are the IQR of the 3 groups?
In Figure 5.9 the medians are not in the middle of the box. This suggest that the distributions might be skewed.
Figure 5.10 presents density plots, similar to histograms, and reveals the same thing.
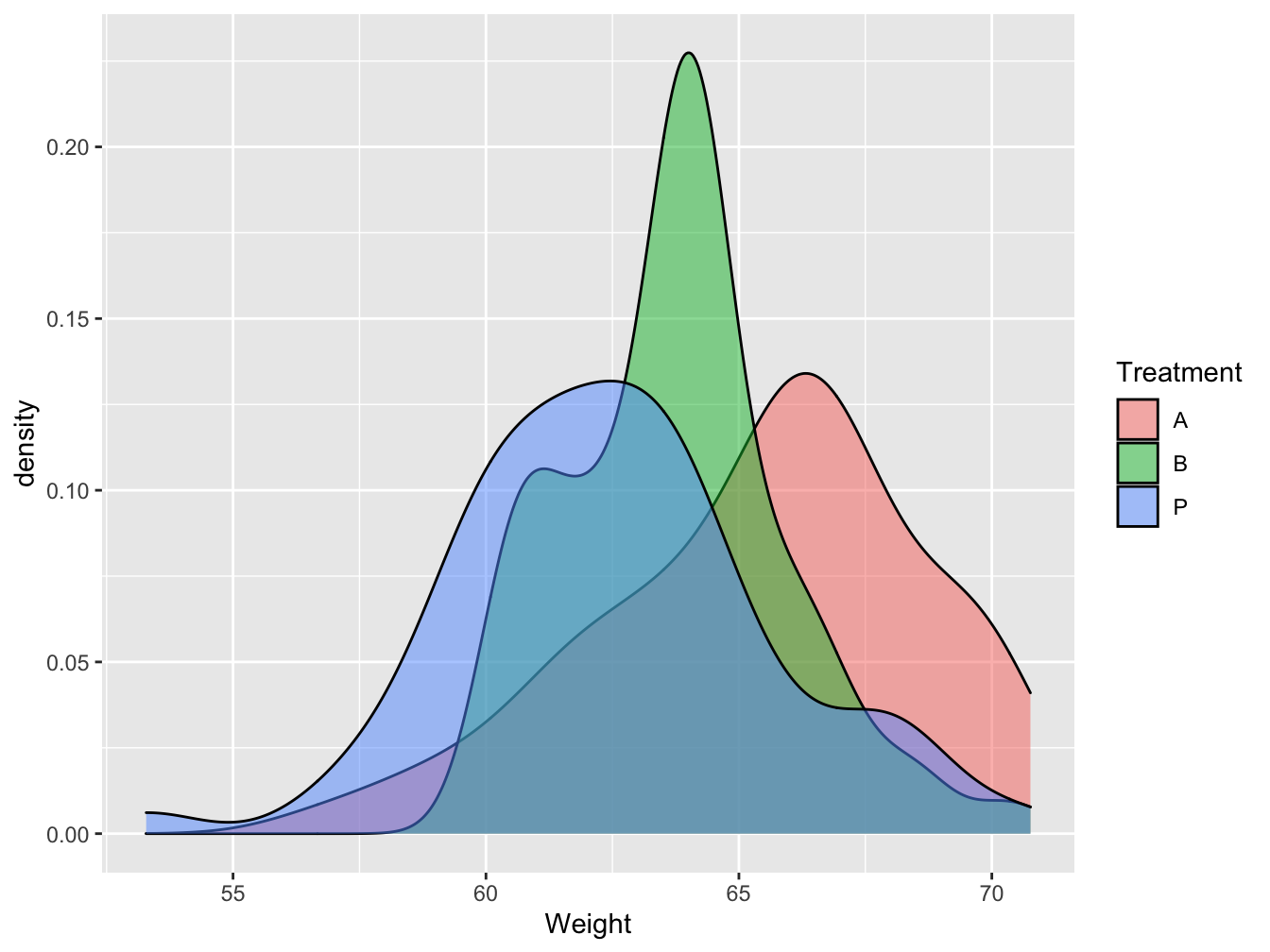
Figure 5.10: Density plots of the effect of different treatments on gain weight
The next step is thus to statistically test the hypothesis of equality of means.
5.6.2 Analysis Of Variance
The Analysis Of Variance or ANOVA allows comparing multiple groups
The Analysis Of Variance or ANOVA systematically compare variability within and between groups. When the variations observed between groups is greater than the within group variation, at least one group is differ from the other.
The statistical hypotheses are:
- H0: \(\mu1 = \mu2 = \mu3 ... = \mu k\) with \(\alpha\)=5%
- H1: At least one mean is different from the other
where \(k\) is the number of independent groups
To that aim we use the F-test (named in honor of Sir Ronald Fisher). The F-statistic is a ratio of two variances that examine variability.
\(F = \frac{Mean Square Between}{Mean Square Error}= \frac{MSB}{MSE}\)
- between groups being compared (Mean Square Between or Mean Square Treatment)
- within the groups being compared (Mean Square Error or Mean Square Residuals)
| Mean Squares | Sums of Squares (SS) | DF |
|---|---|---|
| MSB = SSB/(k-1) | \(SSB = \sum_{i=1}^k n_i(\bar{X_i}-\bar{X})^2\) | k-1 |
| MSE = SSE/(N-k) | \(SSE = \sum_{i=1}^k\sum_{j=1}^n(X_{ij}-\bar{X_i})^2\) | N-k |
| total | \(SST = \sum_{i=1}^k\sum_{j=1}^n(X_{ij}-\bar{X})^2\) | N-1 |
where
DF = degree of freedom
\(X_{ij}\) = individual observation j in treatment i
\(\bar{X_i}\) = sample mean of the \(i^{th}\) treatment (or group/sample)
\(\bar{X}\) = overall sample mean
k = number of treatments or independent groups
n = number of observations in treatment i
N = total number of observations or total sample size
In practice with R
res <- aov(Weight ~ Treatment, data=treatFrame)
summary(res)## Df Sum Sq Mean Sq F value Pr(>F)
## Treatment 2 270.5 135.26 16.48 2.62e-07 ***
## Residuals 183 1501.7 8.21
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1The F-value is the F statistics. The F-value = 16.48 (=135.26/8.21). To conclude under H0 and a given \(\alpha\) risk, we can try to look for the appropriate statistical law and its associated table or we can conclude using the p-value.
The \(p-value = 2.62e^{-07}\). What is your conclusion?
5.6.3 Post-hoc analysis and ANOVA assumptions
The ANOVA results might help you conclude that a least one group varies differently that the others. However you will not know which group. To that aim you, need to perform a post-hoc analysis using the TukeyHSD’s test.
In practice with R
## Tukey multiple comparisons of means
## 95% family-wise confidence level
##
## Fit: aov(formula = Weight ~ Treatment, data = treatFrame)
##
## $Treatment
## diff lwr upr p adj
## B-A -1.667323 -2.883055 -0.45159037 0.0040296
## P-A -2.945509 -4.161241 -1.72977619 0.0000001
## P-B -1.278186 -2.493918 -0.06245338 0.0367906The output of the TukeyHSD’s test presents adjusted p-values (p adj) for the two groups comparisons. In addition is displayed the difference in means (diff) and the lower (lwr) and upper (upr) bounds of the 95% CI on the difference in means.
In example 5, Owing the TukeyHSD’s test, it seems that all means are differ from one another.
That is if we trust the appropriate use of the ANOVA and TukeyHSD’s tests…
The ANOVA analysis relies on several assumptions that need to be tested before computing the ANOVA. The ANOVA formula is a based on mean and variance that can only be used if the distributions are not too different from the Normal distribution. It is a parametric test (see section 5.7). Before the ANOVA we need to verify with prior statistical tests that:
the outcome variable should be normally distributed within each group (Shapiro test)
the variance in each group should be similar (e.g. Bartlett or Levene test)
the observations are independent (not correlated or related to each other)
However, the F-test is fairly resistant or robust to violations of assumptions 1 and 2.
5.7 Parametric and non-parametric test
Parametric tests are those that make assumptions about the parameters of the population distribution from which the sample is drawn. This is often the assumption that the population data are normally distributed. Non-parametric tests are “distribution-free” and, as such, can be used for non-Normal variables. Non-parametric tests are often based on the ranking of the values in the data serie.
For the non-parametric the hypothesis are:
H0: The two samples are from the same distribution
H1: one distribution is shifted in location higher or lower than the other
While for the parametric interested in comparing means the hypothesis are:
H0: The two samples have the same mean
H1: The two samples do not have the same mean
5.7.1 Asessing Normality
- Graphically
Normality can be assess using an histogram or the cumulative distribution function.
In figure @ref(fig:normality_plotfunction), the data normally distributed are on the left where the histogram is symmetric and the cumulative distribution function has a S shape. On the right, the data not normally distributed present a skewed histogram and cumulative distribution function different from a S shape.
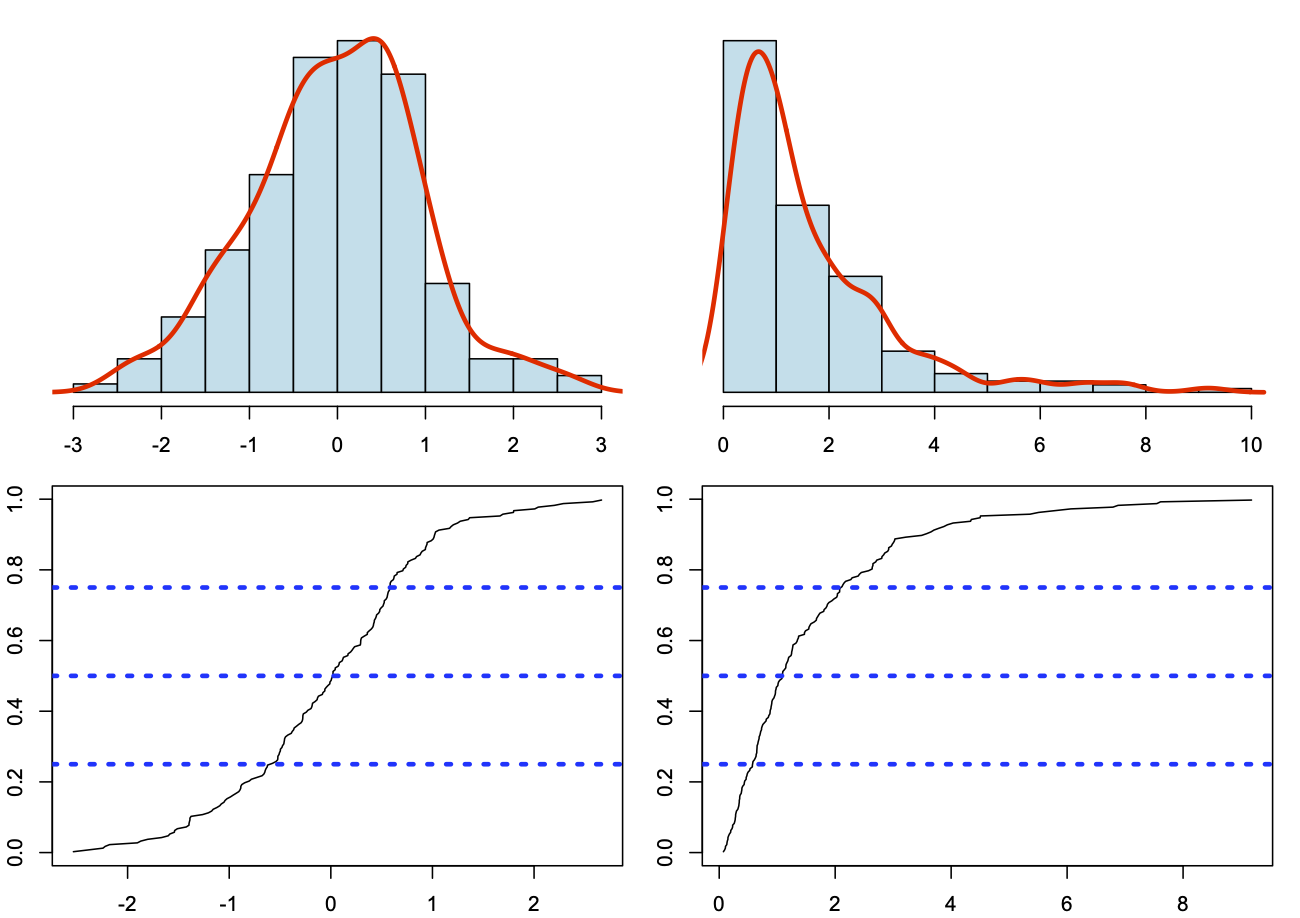
(#fig:distribution function)Assessing normality using graphics
Note that in the skewed distribution, the mean will be largely different from the median and the mode parameters.
- Statistically
The Shapiro-Wilk test or Kolgomorov-Sminorv can be used do verify the normality a distribution. THe statistical hypothesis is:
H0: The sample distribution is equal to the Normal distribution
H1: The sample distribution is different from the Normal distribution
As an example, we randomly generate values drawn from a Normal distribution and test the Normality.
##
## Shapiro-Wilk normality test
##
## data: data
## W = 0.99103, p-value = 0.7475##
## One-sample Kolmogorov-Smirnov test
##
## data: data
## D = 0.094664, p-value = 0.3316
## alternative hypothesis: two-sidedWhat is your conclusion?
Note that the advantage of the Kolgomorov-Smirnov’s test is that it can help assessing other type of distributions than the Normal distribution.
##
## One-sample Kolmogorov-Smirnov test
##
## data: data
## D = 0.50342, p-value < 2.2e-16
## alternative hypothesis: two-sided##
## One-sample Kolmogorov-Smirnov test
##
## data: data
## D = 0.050052, p-value = 0.9636
## alternative hypothesis: two-sidedWhat are your conclusions?
5.7.2 Two-sample Wilcoxon test (or Mann-Whitney U test)
- Given two samples X et Y
- Sort in increasing order the data from X and Y
- Give a rank to the values
- Compute the sum of rank for each sample R1 and R2
- Compute the random variable Un1,n2 = min(Un1, Un2) and the associated Z statistics
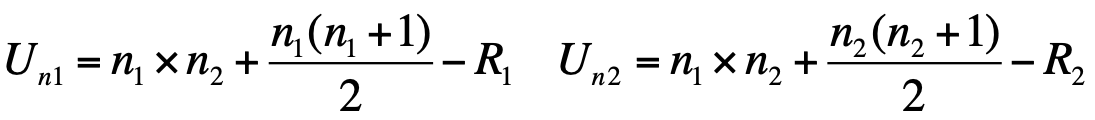
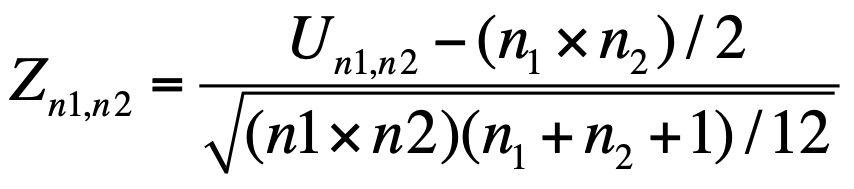
If n1 and n2 < 20, Mann-Whitney’s table
IF n1 and n2 > 20, Normal law table
Example 5.9 Example:
Among diabetes patients, is there a difference in age at diagnosis between men and women?
- Women: 20 11 17 12
- Men: 19 22 16 29 24
Sorting data: 11 12 16 17 19 20 22 24 29
R1 = 1+2+4+6 = 13 and Un1 = 17
R2 = 3+5+7+8+9 = 32 and Un2= 3
Table de Mann-Whitney p-value =0.11
What is you conlusion?
5.7.3 Which test to use?
Non-parametric tests are valid for both non-Normally distributed data and Normally distributed data, so why not use them all the time?
When it is possible to perform both a parametric and a non-parametric test (because we have quantitative measurements) reducing the data to ranks and using the Wilcoxon/Mann-Whitney test will have about 95% of the power of a corresponding two-sample t-test. And, as we have seen, often outliers are interesting in their own right. An analysis that simply ignores them may miss an important fact or instance.
| Parametric | Non-Parametric equivalent |
|---|---|
| Paired t-test | Wilcoxon rank sum test* |
| Unpaired t-test | Mann-Whitney U test* |
| Pearson correlation | Spearmann Correlation |
| One analysis of variance | Kruskal Wallis test |
*In R statistical software, see Wilcoxon.test() and the arguments